One of the most useful features in DITA is Conditional Processing (or Profiling),
which allows you to use the same set of source files to create
different versions of your documentation. Content is marked in a way
that you can filter out entire topics, paragraphs, sentences, and even
words.
DITA offers a set of standard profiling attributes that are applicable to most elements. Those attributes are:
- audience
- platform
- product
- props
- otherprops
- rev
Most of the names are self-explanatory. The props and otherprops attributes are meant to be generic for that you can use for any situation. The rev attribute is meant to identify material that was added or changed during a revision.
Let’s take a look at how you could use these attributes to create different versions of a document.
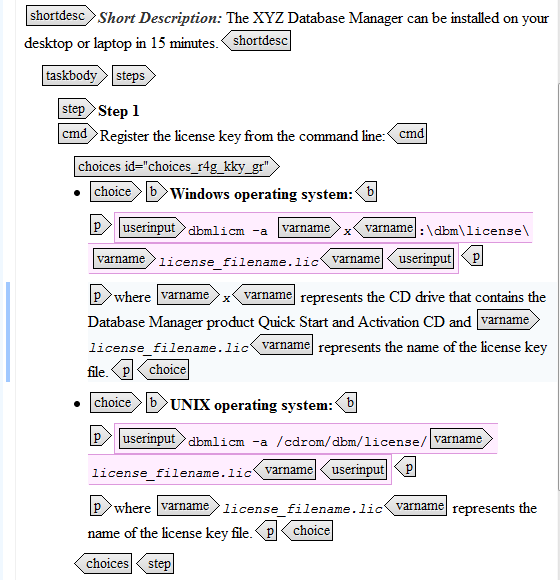
Figure 1 is part of a sample topic for installing a product on either a Windows or a UNIX operating system.

Figure 2 is the source material for the topic.
Your project manager tells you that you have customers that are only
interested in Windows and some that are only interested in UNIX. Add
into that pot folks that are using both Windows and UNIX. Which of
those profiling attributes are you going to use? You got it, platform!
Figure 3 is how you have tagged the source to create docs for each set of customers.

For the customer that is interested in both Windows and UNIX, you
added a platform attribute called all. Then you added an info section
with only the Windows information and tagged it with a platform
attribute called windows. And finally, you added platform attribute
called unix for the the UNIX customers. Now, how do you get those marked
sections to show itself or to hide. The answer is to create a ditaval file.
A ditaval file is used to instruct the transform what to do with your conditional attributes. Figure 4 is the ditaval file I created for the topic.
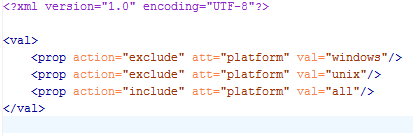
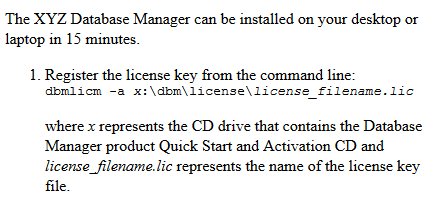
In this ditaval file, only the platform values of all will be displayed. So you would get a topic just like Figure 1 after your transform is completed. If you want to display only the Windows platform, you would edit your ditaval file as shown in Figure 5.

The resulting topic after you transform is shown in Figure 6.
And you would do the similar to create a UNIX only topic.
Now your project manager tells you that your customers want separate documentation for novice and experienced users. So you take a look at your documentation and decide that an experienced user wouldn’t need to be told what the variables (x and license_filename.lic) mean. In this case, you would use the audience attribute on selected paragraphs as in Figure 7.

Paragraphs that only a novice would be interested in are marked with an audience attribute called novice. Before you transform, you need to add the attribute to your ditaval file as seen in Figure 8.

The ditaval instructions now read to include platform attributes called windows, exclude platform attributes called unix and all, and exclude audience attributes called novice. After you transform, you get the topic seen in Figure 9.

We’re not done yet. Now your project manager tells you that have a customer that thinks desktops are history. Therefore, they want only references to the laptop. The offending word is in your short description. Do you want to create two short descriptions and label them with appropriate attributes? You could. Or you could attack the offending words directly using the tag and the props attribute as seen in Figure 10.
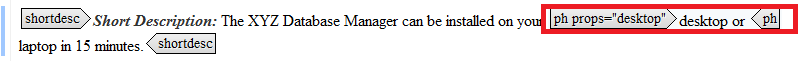
Note that the word or is also tagged. If it isn’t excluded also, the sentence will not make sense.
Now you add the attribute to your ditaval file as in Figure 11.

The ditaval file instructions read to:
- include platform attributes called windows,
- exclude platform attributes called unix and all,
- exclude audience attributes called novice,
- and exclude props attributes called desktop.
This results in the topic seen in Figure 12.

Summary
We only took a look at the platform, audience, and props attributes in this post. I think you get the idea though. DITA’s conditional processing is a powerful and useful feature.